Abstract
How do we reason over biomedical questions when the evidence is scattered across knowledge graphs, literature, and the web?
Biomedical question answering (QA) increasingly requires reasoning over interacting entities, where supporting evidence is scattered across biomedical knowledge graphs, literature documents, and web-accessible resources. However, existing biomedical QA benchmarks mainly focus on exam-style knowledge, literature comprehension, or short-range multi-hop inference, leaving source-conditioned graph reasoning and evidence topology construction underexplored.
To fill this gap, we introduce BioMedHop, a multi-source graph-grounded benchmark for evaluating biomedical reasoning over structured evidence topologies, and propose BioWeave, a source-aware reasoning framework that retrieves biomedical KG paths, gathers supporting clues from documents and web sources, assembles them into a unified evidence graph, and verifies answers through entity-level evidence support.
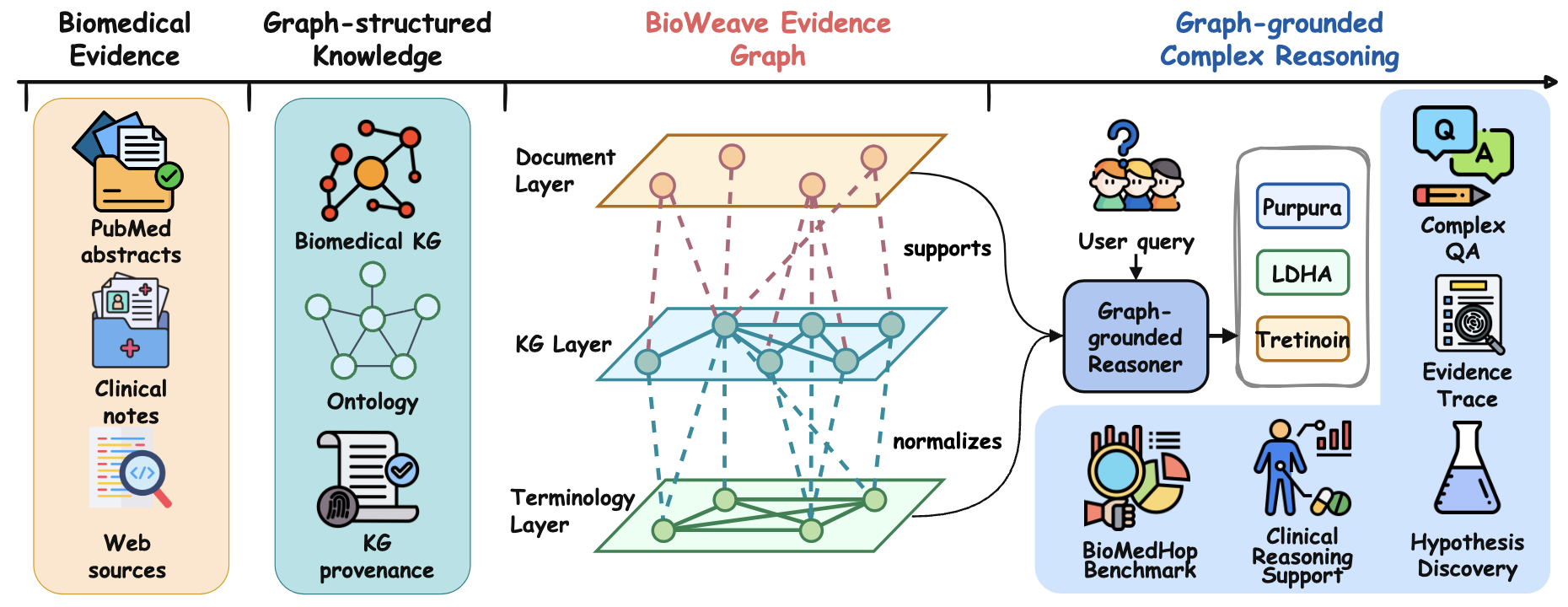
Figure 1: Overview of the BioWeave framework assembling multi-source evidence into a unified biomedical reasoning graph.
BioMedHop Benchmark
📊 Scale & Coverage
BioMedHop contains 10,045 instances spanning four evidence settings: KG-only, document-only, web-accessible, and hybrid. Questions cover shared-neighbor matching, intersection reasoning, path-based reasoning, and counting tasks.
🎯 Rendering Formats
Instances are presented in three formats: option-based (multiple choice), open-ended (free-form), and numeric count (quantitative), enabling evaluation across diverse answer types and reasoning challenges.
🔗 Multi-Source Evidence
Evidence is drawn from biomedical KGs (Monarch, SPOKE), PubMed literature, clinical notes, and web resources. A single question may require connecting genes, diseases, drugs, phenotypes, and clinical outcomes.
🧬 Graph-Grounded Reasoning
Unlike prior benchmarks focused on single-source retrieval, BioMedHop specifically targets source-conditioned graph reasoning and evidence topology construction — the two underexplored dimensions in biomedical QA evaluation.
BioWeave Framework
KG Path Retrieval
Retrieves typed multi-hop paths from biomedical KGs (Monarch, SPOKE), grounding reasoning in validated entity-relation structures with normalized identifiers via UMLS and HPO.
Multi-Source Evidence Gathering
Gathers supporting clues from PubMed abstracts, clinical documents, and web sources, resolving entity synonyms and abbreviations for consistent cross-source entity grounding.
Unified Evidence Graph
Assembles retrieved paths and clues into a unified evidence graph, then verifies answers through entity-level evidence support — making every reasoning step explicit and traceable.
Key Results
Improvement in overall average over the strong hybrid baseline ToG-2 on BioMedHop.
BioWeave enables Qwen3-4B to achieve reasoning performance comparable to GPT-4-Turbo.
BioMedHop instances spanning KG, document, web, and hybrid evidence settings.
BioWeave consistently improves different LLM backbones and achieves best overall performance among all compared methods on BioMedHop.
BibTeX
@article{tan2026bioweave,
title={Weaving Multi-Source Evidence for Biomedical Reasoning: The BioMedHop Benchmark and BioWeave Framework},
author={Tan, Xingyu and Liu, Shiyuan and Wang, Xiaoyang and Liu, Qing and Xu, Xiwei and Yuan, Xin and Zhu, Liming and Zhang, Wenjie},
journal={arXiv preprint arXiv:2606.16211},
year={2026}
}