Abstract
How can we leverage LLM reasoning on private knowledge graphs without leaking sensitive structures or data?
Knowledge graphs (KGs) provide structured evidence that can ground large language model (LLM) reasoning for knowledge-intensive question answering. However, many practical KGs are private, and sending retrieved triples or exploration traces to closed-source LLM APIs introduces leakage risk.
Existing privacy treatments focus on masking entity names, but they still face critical limitations including structural leakage, uncontrolled remote interactions, fragile multi-hop reasoning, and limited experience reuse. PrivGemo is a privacy-preserving RAG framework that uses a dual-LLM (local + remote) design plus privacy-aware memory to reduce both semantic and structural exposure while keeping evidence grounding and verification local.
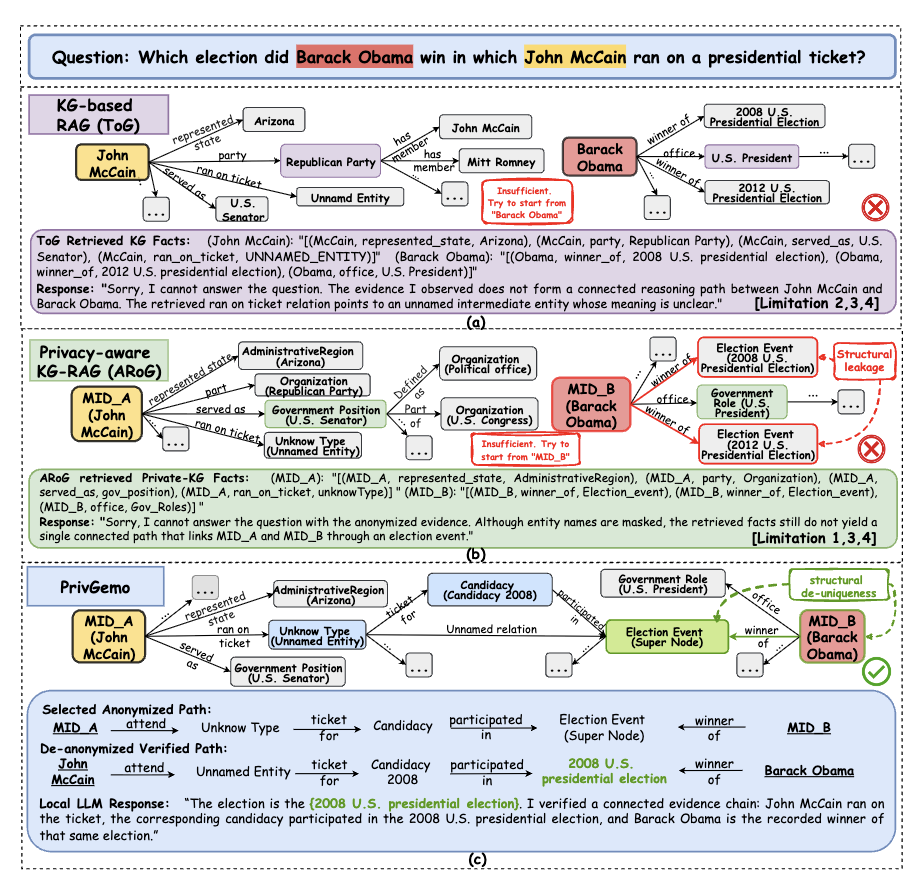
Figure 1: Overview of the PrivGemo framework with privacy-aware memory and dual-LLM hierarchical reasoning.
Addressed Challenges & Solutions
🛡️ Structural Leakage
Issue: Subgraph patterns can reveal entity identities even under semantic masking.
PrivGemo Solution: Implements structure-level sanitization combined with de-uniqueness (normalizing degree distributions) to prevent structural fingerprinting.
🔒 Uncontrolled Remote Interaction
Issue: No control over what information is sent to external APIs.
PrivGemo Solution: Utilizes a Dual-LLM architecture with physical isolation (Local Hand + Remote Brain) and memory gating to restrict data sent outward.
🛤️ Fragile Multi-Hop Reasoning
Issue: Greedy hop-by-hop selection breaks global reasoning chains.
PrivGemo Solution: Employs indicator-guided long-hop path retrieval, allowing multi-stage exploration with forward and backtracking steps.
🧠 Limited Experience Reuse
Issue: No mechanism for stability improvement and efficiency optimization over time.
PrivGemo Solution: Integrates a self-evolving privacy-aware memory with continual learning to store prior search depths, modes, and trajectories.
Key Results
Improvement over the strongest baseline approaches.
Enables smaller local models (e.g., Qwen3-4B) to achieve GPT-4-Turbo level reasoning.
Achieves state-of-the-art results across 6 comprehensive benchmarks.
Code & Implementation
The full source code for PrivGemo, including the dual-tower retrieval pipeline and privacy-aware memory module, is currently being prepared.
BibTeX
@article{tan2026privgemo,
title={PrivGemo: Privacy-Preserving Dual-Tower Graph Retrieval for Empowering LLM Reasoning with Memory Augmentation},
author={Tan, Xingyu and Wang, Xiaoyang and Liu, Qing and Xu, Xiwei and Yuan, Xin and Zhu, Liming and Zhang, Wenjie},
journal={arXiv preprint arXiv:2601.08739},
year={2026}
}